数据库中为什么会有这么多中间表?
中间表是数据库中专门存放中间计算结果的数据表。中间表往往是为了前端查询统计更快或更方便而在数据库中建立的汇总表,这种表是由原始数据加工而成的中间结果,因此被称为中间表。
中间表的出现可能主要有三个原因:
一步算不出来
数据库中的原始数据表要经过复杂计算,才能在报表上展现出来。一个 SQL 很难实现这样的复杂计算。要连续多个 SQL 实现,前面的生成中间表给后边的 SQL 使用。
实时计算等待时间过长
因为数据量大或者计算复杂,报表用户等待时间太长。所以要每天晚上跑批量任务,把数据计算好之后存入中间表。报表用户基于中间表查询就会快很多。
多样性数据源参加计算
来自于文件、NOSQL、Web service 等的外部数据,需要与数据库内数据进行混合计算时,传统办法只能导入数据库形成中间表。
这种中间数据在很多场景下是必要的,那么为什么要把中间数据存储在数据库中形成中间表呢?
主要是为了借助数据库的计算能力。要知道,中间数据在使用时还会做进一步计算,有时计算可能还比较复杂,而目前只有数据库(SQL)具备较为便利的计算能力。
不过,数据库中间表往往会越积越多,在某些大型系统的应用数据库中居然存储高达数万张中间表。为什么会有这么多中间表?中间表过多会带来哪些影响?
由于中间表通常是为前端查询或报表服务的,一个查询就可能对应一张中间表,而报表查询需求很多,这就会产生大量的中间表。更重要的是,中间表一旦产生,通常会永久存储在数据库中,很难删除。原因是由于数据库的扁平结构引起的,数据库表一旦创建就可能被多个查询使用,删除就可能影响其他查询。甚至一个中间表被哪些程序使用都很难搞清楚,更不用提删除了,不是不想删,而是不敢删。日积月累,上万张中间表也就不奇怪了。
中间表过多会带来一系列问题,中间表会占用大量的数据库存储空间导致数据库容量不足,面临扩容压力。我们知道,数据库的空间往往很贵,扩容成本非常高,并且数据库扩容往往存在限制,耗费高昂成本解决中间表问题并不是一个理想的方案。
中间表过多还会引发数据库性能问题,中间表并不是孤立存在,从原始数据到中间表要经过一系列运算这就要耗费数据库计算资源,而且加工中间表的频率可能很高,这样数据库的大量资源消耗在中间表生成上会引起数据库查询慢、性能低等问题。
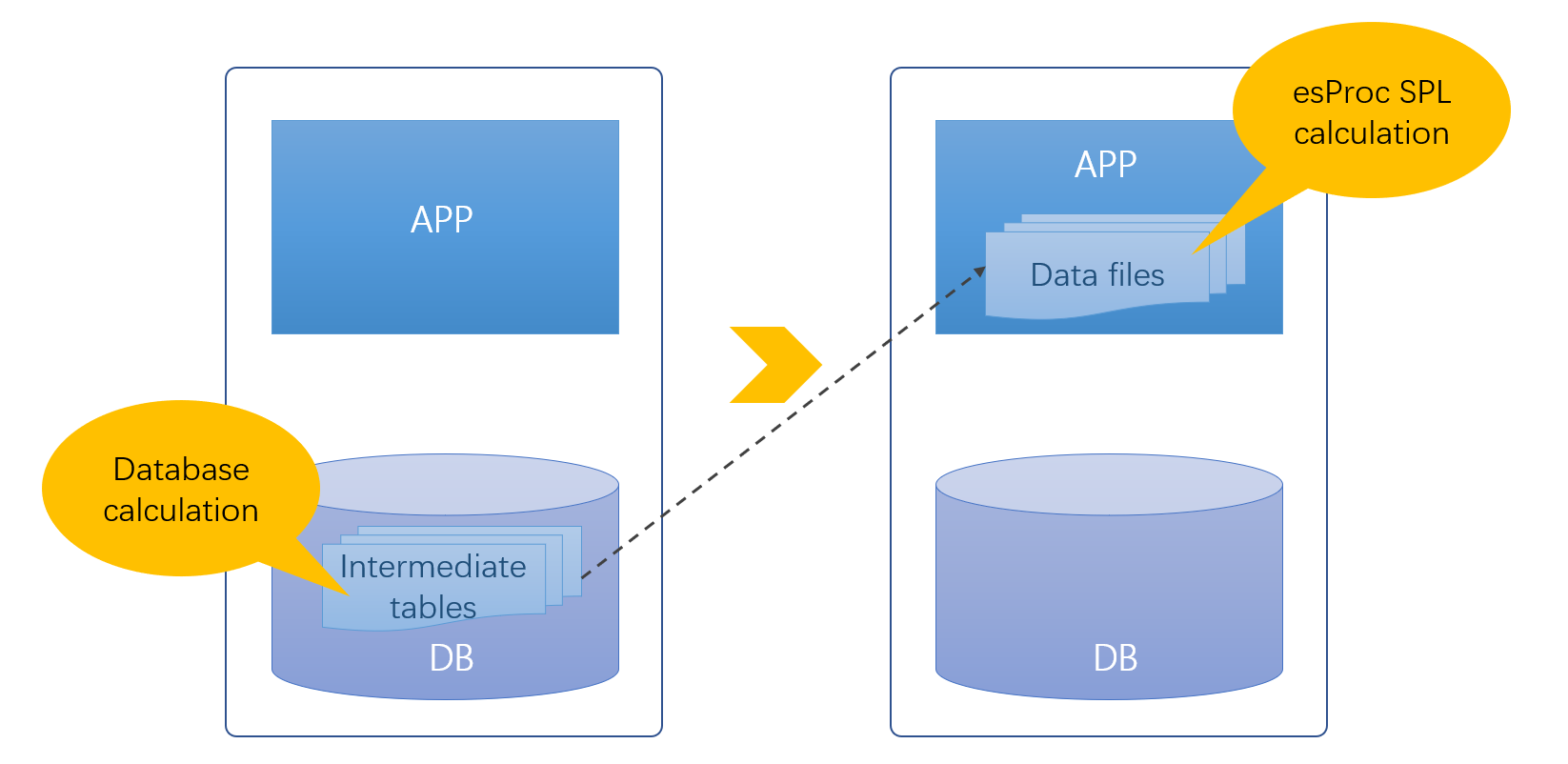
事实上中间表不一定要建立在数据库中,将中间结果数据存储在文件中反而可以获得更高的 IO 性能,使用更灵活的压缩算法,而且也更利于并行。遗憾的是,文件没有计算能力,如果基于文件还要通过 Java 硬编码实施计算,远没有 SQL 方便。
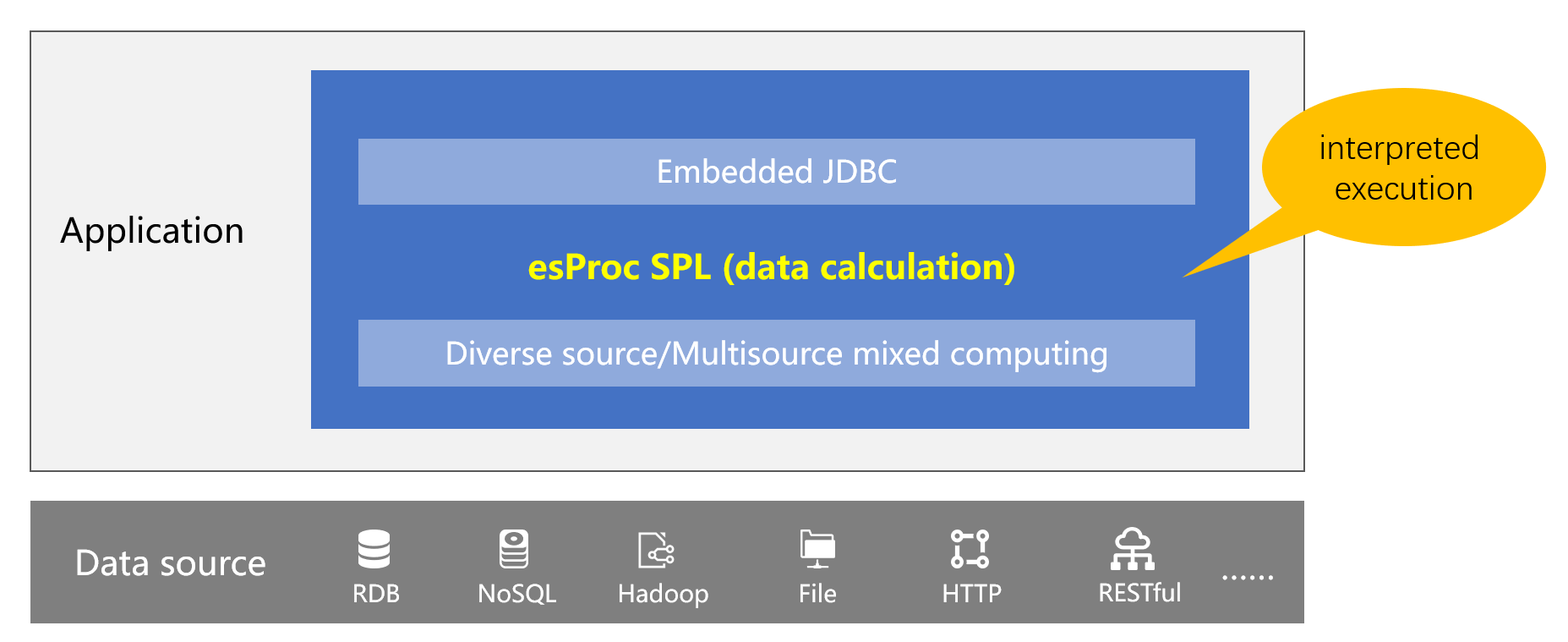
现在好了,使用集算器 SPL 可以很好解决中间表的问题。集算器是一款专业的开源数据计算引擎,其本身具备与数据库一样完备的计算能力。并且,集算器的计算能力不依赖于数据库,可以直接基于文件等数据源实施计算。
借助集算器的如下特征可以轻松搞定中间表过多带来的数据库容量和性能问题。
文件计算
SPL 可以直接基于文件(Excel、CSV、JSON、SPL 二进制)计算,原有的数据库中间表可以直接存储在库外文件中,充分减少数据库中间表数量,缓解数据库压力。
多数据源支持
不仅是文件,SPL 还支持 RDB、NoSQL、Hadoop、RESTApi 等多样性数据源,还可以基于多数据源进行混合计算。这样原来面对多样性数据源需要导入数据库形成中间表的操作就不需要了,直接基于多数据源混算,为查询提供服务。
SPL 敏捷语法
仅仅支持文件和多样性数据源还不够,如果计算复杂度过高(类似 Java)仍然不可用。SPL 的敏捷语法不仅要远优于 Java,很多时候比 SQL 还要简单,越复杂的计算优势越明显。
试举一例:
要找出销售额占到一半的前 n 个客户(大客户)的订单情况。
| A | |
| 1 | =file(“/opt/ods/orders.csv”).import@tc() |
| 2 | =A1.groups(customer;sum(amount):amount).sort(amount:-1) |
| 3 | =A2.sum(amount)/2 |
| 4 | =0 |
| 5 | =A2.pselect((A4=A4+amount,A4>=A3)) |
| 6 | =A2.(customer).to(,A5) |
| 7 | =A1.select(A6.pos(A1.customer)) |
通过分步的方式,先找到符合条件的大客户,再查询这些客户的详细订单信息。从实现的过程来看,SPL 要比原生的 Java 实现结构化数据计算简单太多;也比要嵌套查询的 SQL 更简洁。
SPL 解释执行,支持热部署。
高性能
在性能方面,SPL 内置了大量高性能计算算法,有序计算、多级索引、并行计算等等,还提供了私有二级制的高性能存储格式 BTX 和 CTX,使用高性能存储可以进一步提升运算性能。
集算器可以作为嵌入式 JDBC 与应用集成使用,应用通过 JDBC 方式访问 SPL 计算结果,就像访问数据库一样。
中间表存储在数据库外的文件系统中,使用文件系统的树状结构进行管理,集算器与应用集成后,“库外中间表”就可以随着应用分布,不仅能降低应用与数据库的耦合性,还不会出现多个应用共用同一个中间表的情况,这又将极大方便系统运营。
