Java 怎样解析和生成 xls?
POI提供了全面的功能用以解析和生成xls,但它提供的API过于底层,即使一些简单的读写动作,也要编写大量代码从头写起。全面就意味着要照顾的细节多,各种任务都会显得非常繁琐,硬写代码的量很大。解析和生成的重点通常是数据,但POI在字体、颜色、粗细、对齐等大量的外观属性上投入了大量精力,相对地,数据的进一步处理能力反而并不专业,也只能在外围自己硬编码实现。
一个想法是将poi封装一下,提供更为简洁并擅长数据处理的接口,集算器SPL就是这样的开源库。
对于格式规则的行式xls,SPL的T函数可以用较简洁的代码读取。比如,Excel文件的每行是一条订单记录,首行是列名,读取该文件只需一行代码:
=T("D:/Orders.xls")
对于格式较不规则的行式xls,SPL的xlsimport函数提供了丰富简洁的读取功能。下面举一些常见的例子:
#没有列名,首行直接是数据:
=file("D:/Orders.xlsx").xlsimport()
#跳过前2行的标题区:
=file("D:/Orders.xlsx").xlsimport@t(;,3)
#从第3行读到第10行:
=file("D:/Orders.xlsx").xlsimport@t(;,3:10)
#只读取其中3个列:
=file("D:/Orders.xlsx").xlsimport@t(OrderID,Amount,OrderDate)
#读取名为"sheet3"的特定sheet:
=file("D:/Orders.xlsx").xlsimport@t(;"sheet3")
函数xlsimport还具有读取倒数N行、密码打开文件、读大文件等功能,这里不再详述。
SPL提供了JDBC接口,可以在JAVA里轻松调用。比如解析记录并进行计算:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
String str="=T(\"D:/Orders.xls\").select(Amount>1000 && Amount<=3000 && like(Client,\"*S*\"))";
ResultSet result = statement.executeQuery(str);
…
SPL也擅长对xls进行查询、分组、关联等计算,但那是另一个话题,感兴趣可参考《SPL Excel 计算示例》
对于格式很不规则的xls,SPL的xlscell函数提供了灵活而简洁的读取功能。xlscell的基本功能是读写指定sheet里指定片区的数据,比如读取第1个sheet里的A2格:
=file("d:/orders.xlsx").xlsopen().xlscell("C2")
配合SPL灵活的语法,就可以解析自由格式的xls,比如将下面的文件读为规范的二维表(序表):

这个文件格式很不规则,对POI来说是个浩大的工程,而SPL代码就简短得多:
| A | B | C | |
| 1 | =create(ID,Name,Sex,Position,Birthday,Phone,Address,PostCode) | ||
| 2 | =file(“e:/excel/employe.xlsx").xlsopen() | ||
| 3 | [C,C,F,C,C,D,C,C] | [1,2,2,3,4,5,7,8] | |
| 4 | For | =A3.(~/B3(#)).(A2.xlscell(~)) | |
| 5 | if len(B4(1))==0 | Break | |
| 6 | >A1.record(B4) | ||
| 7 | >B3=B3.(~+9) | ||
上面的SPL代码以脚本文件的形式外置于JAVA代码,修改时无需编译,可大幅降低耦合性,适合较复杂或频繁修改的解析或计算过程。JAVA代码可以用存储过程的方式调用上面的脚本文件:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
ResultSet result = statement.executeQuery("call getEmps()");
...
SPL提供了专业的IDE,适合设计逻辑复杂的解析过程,不仅具备完整的调试功能,还可以观察每一步的中间结果。
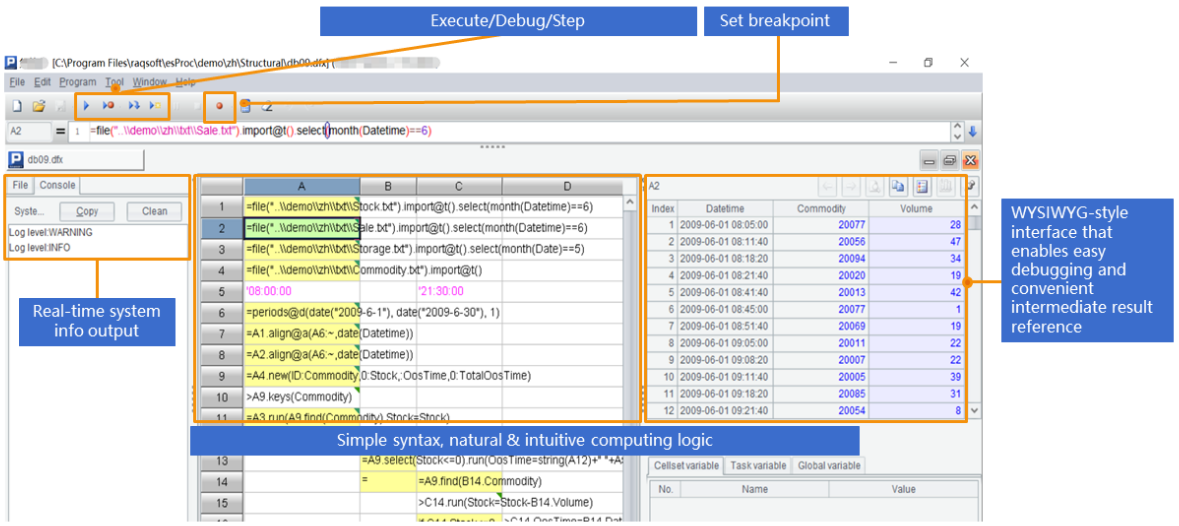
说完解析,再讲讲Excel的生成。
SPL可用简洁的代码生成xls,掌握起来非常容易。比如上面例子的解析结果是个序表,存在SPL的A1格中,下面将A1写入xls的第一个sheet,首行为列名,只需一句代码:
| A | B | C | |
| … | |||
| 8 | =file("e:/result.xlsx").xlsexport@t(A1) |
SPL提供了丰富的生成功能,可以将序表写入指定sheet,或只写入序表的部分行,下面是个具体例子:将序表中指定的列写入Excel。
| =file("e:/scores.xlsx").xlsexport@t(A1,No,Name,Class,Maths) |
SPL可以方便地追加数据,比如对于已经存在且有数据的xls,将序表A1追加到该文件末尾,风格与末行保持一致:
| =file("e:/scores.xlsx").xlsexport@a(A1) |
前面提到的xlscell函数不仅有读取功能,也具有同样灵活简洁的写入功能,可以在不规则不连续的指定单元格中填入数据。比如,上级发来的xls中蓝色单元格是不规则的表头,下级需要在相应的白色单元格中填入数据,填好之后应当如下:
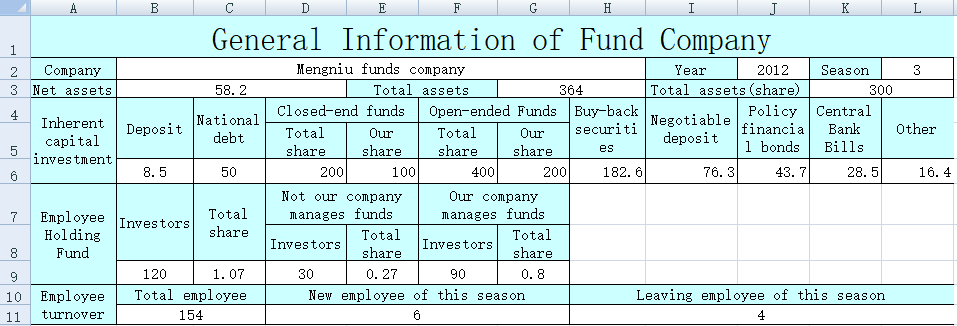
要实现上面不规则的数据填入,POI要大段冗长的代码,而SPL代码就简短许多(其中A1: F5格是待填的数据):
| A | B | C | D | E | F | |
| 1 | Mengniu Funds | 2017 | 3 | 58.2 | 364 | 300 |
| 2 | 8.5 | 50 | 200 | 100 | 400 | 200 |
| 3 | 182.6 | 76.3 | 43.7 | 28.5 | 16.4 | |
| 4 | 120 | 1.07 | 30 | 0.27 | 90 | 0.8 |
| 5 | 154 | 6 | 4 | |||
| 6 | =file("e:/result.xlsx") | =A6.xlsopen() | ||||
| 7 | =C6.xlscell("B2",1;A1) | =C6.xlscell("J2",1;B1) | =C6.xlscell("L2",1;C1) | |||
| 8 | =C6.xlscell("B3",1;D1) | =C6.xlscell("G3",1;E1) | =C6.xlscell("K3",1;F1) | |||
| 9 | =C6.xlscell("B6",1;[A2:F2].concat("\t")) | =C6.xlscell("H6",1;[A3:E3].concat("\t")) | ||||
| 10 | =C6.xlscell("B9",1;[A4:F4].concat("\t")) | =C6.xlscell("B11",1;[A5:C5].concat("\t")) | ||||
| 11 | =A6.xlswrite(B6) | |||||
注意,第6、9、11行有连续单元格,SPL可以简化代码一起填入,POI只能依次填入。
总之,在解析和生成xls方面,经过精心封装的SPL要比POI更方便更简洁,在读写不规则文件时,这种优势尤其明显。
