微服务中的数据处理逻辑就用Java硬写吗?
为了保证微服务的可扩展性数据库往往主要做数据持久化,而不过多承担数据处理的工作,数据处理主要在应用端通过 Java 完成。这样可以解耦应用和数据库,数据库更换或扩容都不会对微服务产生过大影响,充分发挥微服务的效力。
那么微服务中的数据处理逻辑只能使用 Java 硬编码吗?
要回答这个问题,我们要梳理一下目前能实现微服务中数据处理工作的技术还有哪些。
数据库 SQL
强依赖数据库处理数据会影响微服务扩展。在具体实施时,如果多个微服务共享一个数据库会引发单点故障;如果采用一对一方式按业务拆分的微服务会面临分布式事务、数据分布以及跨服务请求数据计算困难等问题。这种方式严重违背了微服务的设计原则,因此很少采用。
其他开发语言
除了 Java 和 SQL 还有一些具备一定数据处理能力的开发语言,比如 Scala、Python 和 Kotlin。这些技术要么使用门槛较高(如 Scala),要么很难跟 Java 微服务框架结合(如 Python),要么实施计算不方便(如 Kotlin),要么不支持热部署(如 Scala 和 Kotlin)。这些技术与 Java 比起来并没有太多长处,反而因为目前主流的微服务框架都基于 Java 开发,使用 Java 处理数据天然适配。
那么使用 Java 处理数据有哪些优缺点呢?
显而易见的优点是与主流微服务框架的无缝结合,其次基于 Java 可以实施分步计算。不过,Java 的缺点也非常明显。Java 缺乏结构化计算类库,实现数据处理非常困难,简单的分组运算也要几十行代码,复杂计算的编码量简直难以承受,即使 Java8 以后引入 Stream 也并无明显改善。这方面就远没有 SQL 方便了。此外,Java 作为编译型语言很难热部署,对多变的微服务场景并不友好。
由此可见,其他技术无法满足微服务数据处理要求,就只能硬着头皮用 Java 硬编码了,虽然困难,但相对其他技术还是有优势的。
集算器 SPL 的出现改变了这个现状,使用集算器进行微服务数据处理可以很好地继承 Java 的优点并改善其缺点。集算器是一款开源数据处理引擎,不仅能与 Java 应用(微服务框架)无缝集成,还提供了完备的计算能力,基于集算器的 SPL 语法实施计算的简便性远超 Java(甚至 SQL),为微服务数据处理提供了新思路。
数据源方面,集算器支持多种数据源类型,RDB、NoSQL、Json、CSV、HDFS、RESTApi 等,还可以基于这些数据源混合计算。
在数据处理算法实现方面,集算器采用自有的 SPL 语法,下面的例子可以感受到 SPL 的简洁程度。
根据股票记录表查询股价连续上涨超过 5 天的股票及上涨天数(股价相等记为上涨)
| A | ||
| 1 | =db.query@x("select * from stock_record order by ddate") | |
| 2 | =A1.group(code) | |
| 3 | =A2.new(code,~.group@i(price<price[-1]).max(~.len())-1:maxrisedays) | 计算每只股票的连续上涨天数 |
| 4 | =A3.select(maxrisedays>=5) | 选出符合条件的记录 |
从数据库取数后,通过 SPL 实施计算,这个例子即使使用 SQL 也要嵌套 3 层子查询才能实现,更不用说 Java(Stream,也包括 Kotlin)了。SPL 支持分步计算,这方面也要优于 SQL。
SPL 是解释执行的,支持热切换,计算脚本修改无需重启服务,这点是其他编译型语言无法比拟的。
集算器可以作为嵌入式 JDBC 与微服务框架集成使用,应用通过 JDBC 方式访问 SPL 计算结果,就像访问数据库一样。
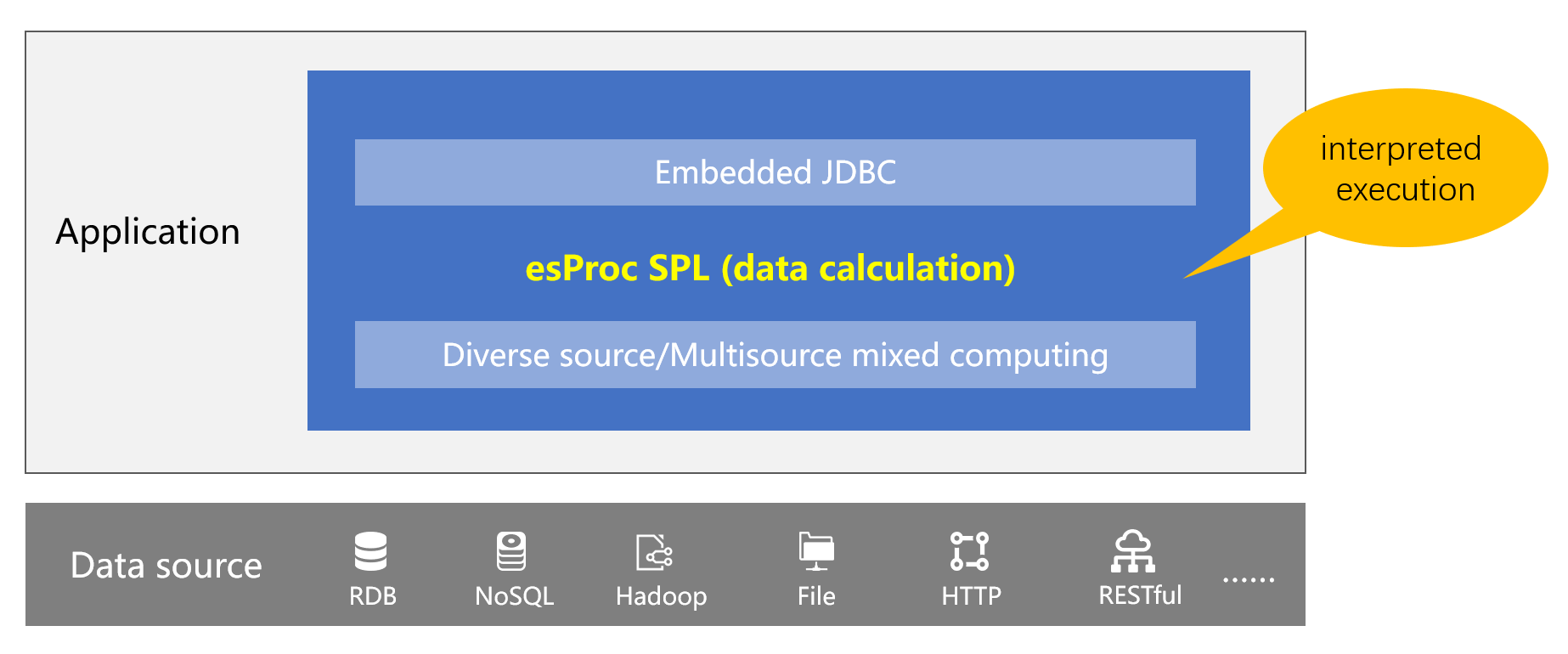
总体来看,集算器几乎结合了其他实现方式的所有优点,具备 all-in-one 的特征。相对 SQL,SPL 支持分步计算实现复杂计算更加简单;相对 Java 则提供了丰富的计算类库,算法更加简洁;相对 Scala 也更简单;相对 Python 除了语法简洁又可以与微服务框架无缝嵌入更易使用,是相对理想的微服务数据处理手段。
