多数据源混合计算用什么技术?
现代信息系统多数据源的情况很常见,尤其分析型应用经常要跨多数据源混合计算实现数据统计分析。由于数据源种类众多,有 RDB,也有 NoSQL,还有 CSV、Excel 等文件,JSON、XML 数据,HDFS、Elasticsearch、Kafka 等很多很多,要基于这些不同类型的数据源进行混合计算并不容易。难点在于各个数据源的计算能力不同,RDB 计算能力较强,使用时可以依赖其计算能力,但 NoSQL 的计算能力较弱,而文件完全没有计算能力,这就需要一种不依赖数据源计算能力的通用技术来解决跨源计算问题。
以往一些跨源计算方案都存在这样那样的缺点,比如以 DBLink 为代表的跨库查询方案,不仅稳定性和效率很差,还只能基于数据库;Scala 不仅使用有难度,还只能全内存;Calcite 功能单一且性能极差,都不理想。
那么还有没有什么技术能有效应对多数据源混合计算的问题呢?
答案是肯定的,可以使用开源集算器 SPL 来解决。
SPL 是一款专业的开源数据计算引擎,提供了不依赖数据源的独立计算能力,可以对接多种数据源,还可以进行混合计算。
多源支持与混合计算
SPL 直接支持几十种数据源(仍在扩展中),无论数据源有无计算能力都可以连接计算。

SPL 支持的部分数据源
SPL 在使用这些数据源时可以充分保留各类数据源的优点,比如 RDB 的计算能力较强,在很多场景下就可以让 RDB 先完成一部分计算后再由 SPL 接管;NoSQL 和文件的 IO 传输效率很高 SPL 就可以直接读取计算;MongoDB 支持多层数据存储,SPL 直接使用会很方便……
更重要的是,SPL 可以基于这些数据源混合计算。比如常见的跨库计算场景(跨库混合计算):
| A | |
| 1 | =oracle.query("select EId,Name from employees") |
| 2 | =mysql.query("select SellerId, sum(Amount) subtotal from Orders group by SellerId") |
| 3 | =join(A1:O,SellerId; A2:E,EId) |
| 4 | =A3.new(O.Name,E.subtotal) |
以及冷热数据分离后全量 T+0 查询场景(文件与数据库混合计算):
| A | ||
| 1 | =cold=file(“/data/orders.ctx”).open().cursor
(area,customer,amount) |
/ 冷数据从文件系统(SPL 高性能存储)中取,昨天及以前的数据 |
| 2 | =hot=db.cursor(“select area,customer,amount from orders where odate>=?”,date(now())) | / 热数据从生产库中取,今天的数据 |
| 3 | =[cold,hot].conjx() | |
| 4 | =A3.groups(area,customer;sum(amout):amout) | / 混合计算实现 T+0 |
还有 JSON/XML 多层数据与数据库关联查询:
| A | ||
| 1 | =json(file("/data/EO.json").read()) | JSON数据 |
| 2 | =A1.conj(Orders) | |
| 3 | =A2.select(Amount>1000 && Amount<=3000 && like@c(Client,"*s*")) | 条件过滤 |
| 4 | =db.query@x(“select ID,Name,Area from Client”) | 数据库数据 |
| 5 | =join(A3:o,Client;A4:c,ID) | 关联计算 |
同样 MongoDB 等 NoSQL 也可以:
| A | |
| 1 | =mongo_open("mongodb://127.0.0.1:27017/mongo") |
| 2 | =mongo_shell(A1,"test1.find()") |
| 3 | =A2.new(Orders.OrderID,Orders.Client,Name,Gender,Dept).fetch() |
| 4 | =mongo_close(A1) |
| 5 | =db.query@x(“select ID,Name,Area from Client”) |
| 6 | =join(A3:o, Orders.Client;A4:c,ID) |
再比如 RESTful 数据与文本数据混用:
| A | ||
| 1 | =httpfile("http://127.0.0.1:6868/api/getData").read() | RESTful数据 |
| 2 | =json(A1) | |
| 3 | =T(“/data/Client.csv”) | 文本数据 |
| 4 | =join(A2:o,Client;A3:c,ClientID) | 关联计算 |
不管何种数据源,连接以后的计算方式都是一样的,这就是一致性计算能力的威力。除了原生 SPL 语法,SPL 还提供了相当 SQL92 标准的 SQL 支持,使用 SQL 语法也可以完成跨数据源计算。
比如 CSV 与 Excel 混合计算的 SQL 写法:
$select o.OrderId,o.Client,e.Name e.Dept from d:/Orders.csv o inner join d:/Employees.xls e on o.SellerId=e.Eid
MongoDB 与数据库之间使用 SQL 混合查询:
| A | |
| 1 | =mongo_open("mongodb://127.0.0.1:27017/mongo") |
| 2 | =mongo_shell@x(A1,"detail.find()").fetch() |
| 3 | =db.query@x("select * from main") |
| 4 | $select d.title, m.path,sum(d.amount) from {A2} as d left join {A3} as m on d.cat=m.cat group by d.title, m.path |
无论是 SPL 原生语法,还是 SPL 支持的 SQL 语法,都可以在各类数据源上使用,语法不受数据源种类限制更加通用。
完备的计算能力与一致的语法风格
SPL 提供了完备的计算能力,所有结构化数据计算都能完成,同时还提供了丰富的计算类库,支持过程计算,使得计算不仅能实现还很简单。
这样,基于 SPL 的强计算能力与一致的语法风格,面对多样性数据源时就获得了通用一致的计算能力。不仅技术路线统一,开发维护也很方便,程序员无需掌握不同数据源数据的处理方法,学习成本也更低。特别的,统一的技术路线具备更强的移植性,数据源变化只需要更改取数代码即可,主要的计算逻辑无需更改,移植性超强。
易集成
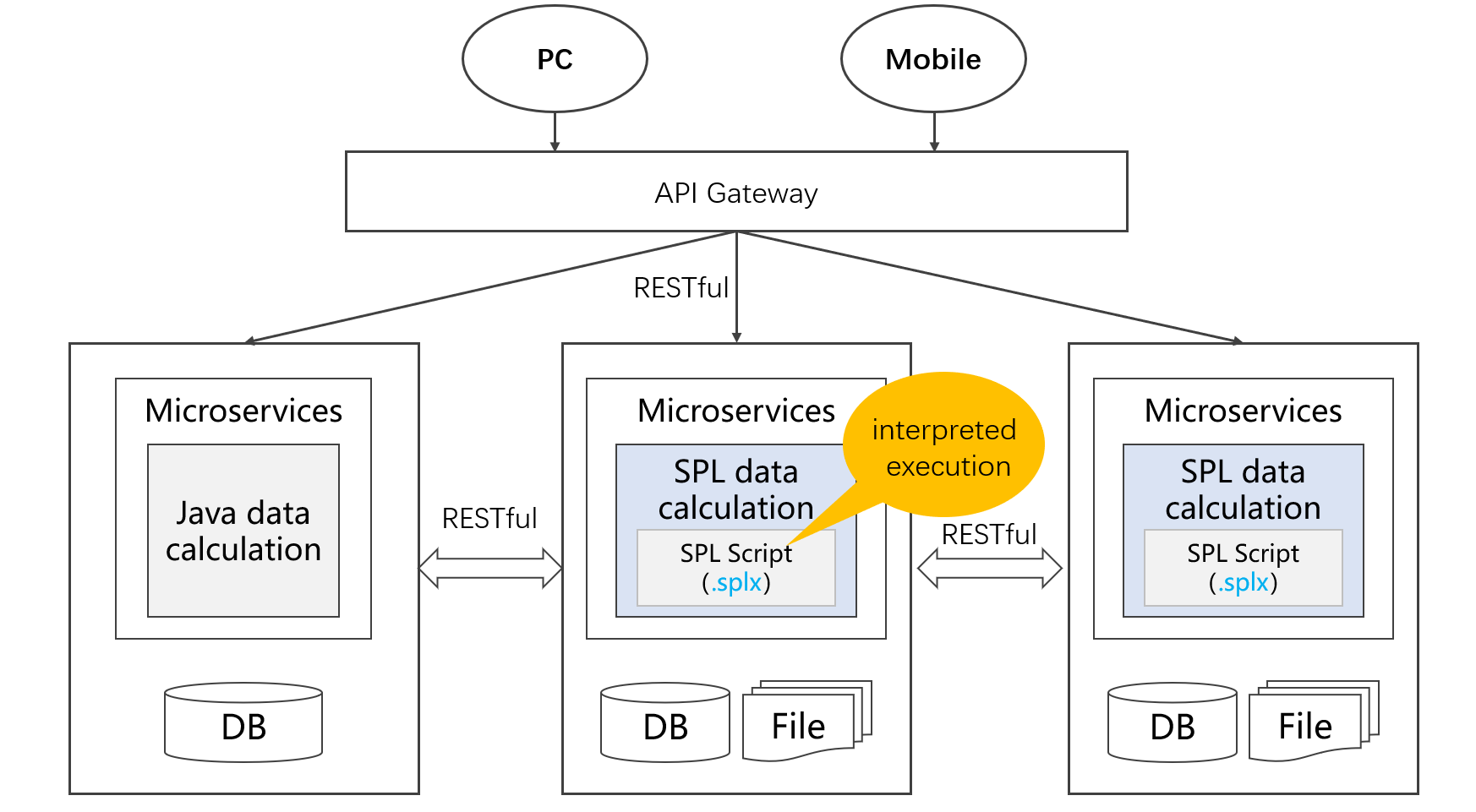
SPL 提供了标准应用接口(JDBC/ODBC/RESTful)可以很方便与应用集成。尤其对于 Java 应用可以将 SPL 作为嵌入引擎集成,使得应用本身就具备多数据源混合计算能力。
JDBC 调用 SPL 代码示例:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
CallableStatement st = conn.prepareCall("{call splscript(?, ?)}");
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
…
SPL 解释执行支持热切换,综合易集成、易开发这些特性还很方便与主流的微服务框架结合,实现服务内的数据处理工作,有效减轻原来 Java 实施数据计算的负担。
SPL 相对其他多源混算方案更加完整,能力也更强,使用起来也更轻,非常适合在当代应用的多源场景下使用。
