微服务实施数据处理的方法
一个完整的微服务包括服务治理(注册 / 发现 / 注销)、服务网关、服务容错、服务通信、服务监控、服务安全、部署与编排等诸多内容。使用原生开发语言从头开发往往不太现实,因此在实现微服务时通常会使用已有微服务开发框架进行搭建,如 Spring Cloud、Dubbo、Istio 等。
而微服务中数据处理是核心,也是工作量较大而框架本身不能帮上忙的地方,对于分析型业务,数据计算更是核心中的核心。本文将基于微服务开发框架(Spring Cloud)探讨微服务中实施数据计算的方法并比较。比较点大概包括如下方面:
- 应用难度,是否方便与微服务框架集成
- 算法实现难度,算法实现是否简单
- 计算能力,是否具备强计算能力从而能够完成所有计算任务
- 耦合性,是否会存在服务与服务、服务与数据源强耦合
- 热部署,修改算法是否支持不停机热切换
- 扩展性,是否能够提供可扩展的计算能力
Java
包括 Spring Cloud 在内的多数主流微服务开发框架默认开发语言都是 Java,使用 Java 实施数据处理可以与微服务框架无缝结合,而且可以随应用根据需要进行任意扩展。在微服务架构中的位置如下:

那么使用 Java 实施微服务数据处理有哪些选择呢?
Stream
在 Java8 以后引入了惰性(Lazy Evaluation)集合计算库 Stream 使得 Java 在集合运算能力方便得到大幅增强,Lambda 语法在计算表达上也变得更加简洁。
//整数组过滤 IntStream iStream=IntStream.of(1,3,5,2,3,6); IntStream r1=iStream.filter(m->m>2); //排序 Stream r2=iStream.boxed().sorted();
不过,Stream 在面对记录类型运算时却很吃力,而记录才是微服务数据处理的重点。比如对订单表的 Client 字段逆序排序,对 Amount 字段顺序排序,代码如下:
// Orders是Stream类型,Order是记录类型,定义如下: //record Order(int OrderID, String Client, int SellerId, double Amount, Date OrderDate) {} Stream result=Orders .sorted((sAmount1,sAmount2)->Double.compare(sAmount1.Amount,sAmount2.Amount)) .sorted((sClient1,sClient2)->CharSequence.compare(sClient2.Client,sClient1.Client));
可以看到代码就不那么简洁了(相对 SQL 要复杂得多),排序字段还要前后颠倒,有点不习惯。另外,代码中的数据对象 record 会自动实现 equals 函数,如果采用 entity,还需手工实现该函数才能支持排序计算,代码长度又会增加。
此外,通过 Stream 实施关联计算也并非易事,硬编码实现的关联计算不仅冗长,而且逻辑复杂。左关联和外关联的代码同样要硬编码,关键的代码逻辑还不一样,编写起来难度更大,这对专业 JAVA 程序员来说都是个挑战。究其原因,仍然是 Java 缺乏专业的结构化计算类库导致,虽然 Stream 有所增强,但仍远远不够。
Java 作为编译型语言不支持热部署,这对可能频繁修改微服务计算逻辑是个不小的挑战。
关于使用 Stream 进行数据处理更多的内容可以参考《Stream 能在 Java 中取代 SQL 吗》。
Java 计算库
鉴于 Stream 的缺陷,在一些特定数据计算场景下还可以选择第三方 Java 计算库完成数据处理。Java 计算库的选择有两种,一种借助 SQL 的能力来弥补 Java 的缺点;另一种是借助类似 Python Pandas DataFrame 的对象来简化数据处理。
提供 SQL 能力的 Java 计算库包括 CSVJDBC/XLSJDBC/CDATA Excel JDBC/xlSQL 等,从名称可以看出来,这类工具主要以文件计算为主。不过这些计算库大多不够成熟,以其中相对成熟的 CSVJDBC 为例,其具备良好的集成性通过 jar 包就可以与 Spring Cloud 集成使用,在实施计算时可以使用 SQL 完成。不过 CSVJDBC 仅支持有限几种计算,比如条件查询、排序、分组汇总,而集合运算、子查询、关联计算等都不支持。不仅如此,CSVJDBC 只能以 CSV 为数据源,其他类型数据源要转换成 CSV 才能计算,这些都大大限制了使用场景。
DataFrame 类 Java 计算库包括 Tablesaw/Joinery/Morpheus/Datavec/Paleo/Guava 等,与 CSVJDBC 类似,这类工具的成熟度仍然不高。以 Tablesaw 为例,其集成性良好通过 jar 包就可以与 Spring Cloud 集成。在计算方面可以完成排序、分组汇总以及关联运算,但对复杂计算支持不好,虽然有 Lambda 语法加持,但仍然需要复杂编码。
关于 Java 计算库更详细内容可以参考《四类 JAVA 计算层的深度对比》。
SQL
相对 Java 使用 SQL 实现微服务中的数据处理会更加简单方便,那么使用对 SQL 支持更好的数据库尤其是 RDB 也会是一种选择。
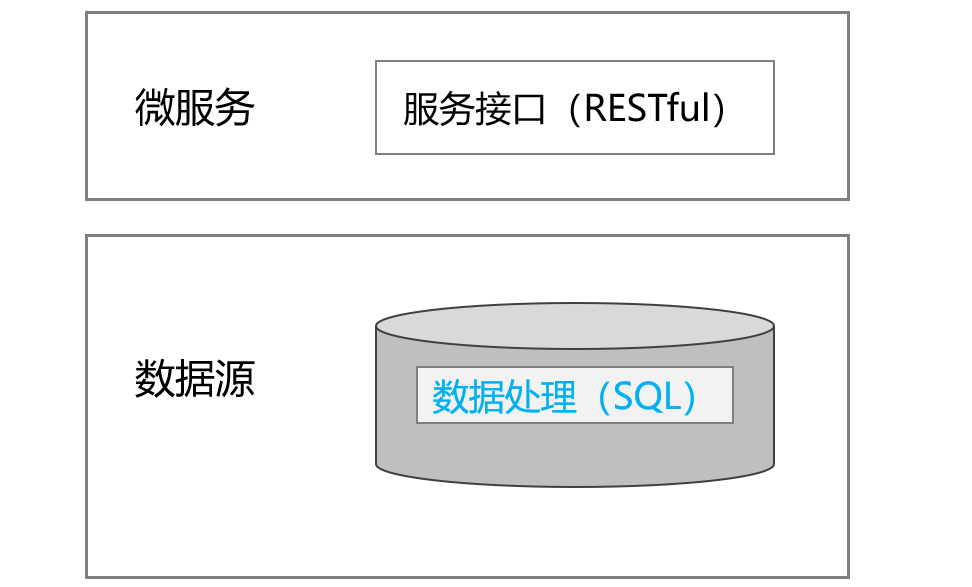
SQL 实现计算相对 Java 是要简单的多,但将数据处理的工作下沉到数据库中缺点也很明显。首先,微服务架构的数据库如何设计?多个微服务共享同一个数据库,还是每个微服务对应一个数据库?如果采用共享方案,势必会引起多个服务之间的耦合性问题,而且极易引发单点故障导致服务失效。如果采用一对一的方案,又会引起数据分布和使用的矛盾。
我们知道,微服务是按照业务进行拆分和设计的,对于 TP(交易型)场景分布式事务本身就是非常棘手的难题。而对于更侧重数据处理的 AP(分析型)场景,微服务拆分后如何进行数据分布,毕竟分析型场景的数据量都很大,且业务查询涉及的数据范围非常广,如果在每个数据库中都存储全量数据那么数据传输和维护成本会非常高。如果仅存储部分数据当查询涉及多个服务数据时就会涉及跨服务数据调用。为了遵循一库一服务的原则,不允许其他微服务直接访问本服务的数据库,这就要通过服务封装的数据访问接口进行数据访问,多个服务数据取到某处再通过 Java 实施计算,这就又面临 Java 做数据处理的各种难题。
实际应用时,共享数据库的情况并不多见,因为这样做严重违背了微服务的设计原则,使微服务失去意义,缺点也十分明显。而一对一的方案无论从应用难度还是维护成本方面都需要极大投入。不仅如此,将数据处理逻辑放到数据库中还会导致服务与数据库的紧耦合,不利于服务扩展和数据库更换。因此使用数据库做数据持久化存储,而将大部分数据处理工作放到应用端(如使用 Java)仍然是主流做法。
Java 虽然与微服务框架联系紧密但实现数据处理过于复杂,SQL 虽然简单但碍于数据库限制则很少主要用于数据处理。那么还有其他技术可以实现微服务中的数据处理吗?
Scala
Scala 的设计初衷是通用开发语言,但真正引起人们注意的,是它专业的结构化数据计算能力,这既包括 Spark 架构的分布式计算,也包括无框架无服务的本地计算。Scala 运行于 JVM 之上,天生就容易被 JAVA 集成。这就可以借助 Scala 的优势,将其嵌入微服务框架中提供数据处理能力。

可以感受一下 Scala 实现数据处理的代码,总体来说还算简单。
//条件查询
val condtion=Orders.where("Amount>1000 and Amount<=3000 and Client like'%S%' ")
//排序
val orderBy=Orders.sort(asc("Client"),desc("Amount"))
//分组汇总
val groupBy=Orders.groupBy(year(Orders("OrderDate"))).agg(sum("Amount"))
//关联
val Employees = spark.read.option("header", "true").option("sep","\\t")
.option("inferSchema", "true")
.csv("D:/data/Employees.txt")
val join=Orders.join(Employees,Orders("SellerId")===Employees("EId"),"Inner")
.select("OrderID","Client","SellerId","Amount","OrderDate","Name","Gender","Dept")
Scala 作为编译型语言不支持热部署,这个缺点与 Java 类似。此外,Scala 的学习门槛较高,这可能也是其一直比较小众的原因之一。
Kotlin
与 Scala 类似,Kotlin 也是一种可以运行在 JVM 上的编译型开发语言。使用 Kotlin 可以与 Spring Cloud 等微服务框架结合完成数据处理任务。与 Scala 不同的是很多 IDE 内置了 Kotlin 语言选项,构建 Spring Cloud 项目时可以选择 Kotlin 无需再手动引入。
在计算表达方面,Kotlin 可以认为是增强版 Stream,简化了 Lamda 语法,增加了热情(Eager Evaluation,与惰性相对)的集合计算,并补充了很多集合函数。
不过,当面对复杂结构化数据计算时 Kotlin 的表现与 Stream 并无明显改善。
比如对订单表的 Client 字段逆序排序,对 Amount 字段顺序排序:
//Orders是List类型,Order定义如下: //data class Order(var OrderID: Int,var Client: String,var SellerId: Int, var Amount: Double, var OrderDate: Date) var resutl=Orders.sortedBy{it.Amount}.sortedByDescending{it.Client}
多字段分组汇总,即按年份和Client分组,对Amount求和并计数:
data class Grp(var OrderYear:Int,var SellerId:Int)
data class Agg(var sumAmount: Double,var rowCount:Int)
var result=Orders.groupingBy{Grp(it.OrderDate.year+1900,it.SellerId)}
.fold(Agg(0.0,0),{
acc, elem -> Agg(acc.sumAmount + elem.Amount,acc.rowCount+1)
})
.toSortedMap(compareBy { it. OrderYear}.thenBy {it. SellerId})
result.forEach{println("group fields:${it.key.OrderYear}\\t${it.key.SellerId}\\t aggregate fields:${it.value.sumAmount}\\t${it.value.rowCount}") }
单字段分组汇总时,可以用 Map 里的 key 存储分组字段(value 类似),多字段分组汇总就不能这么干了,因为 key 里不能放多个字段。这种情况下可以定义一个有结构的数据对象 Grp,把多个分组字段拼进这个对象里,再用 key 来存储 Grp。由于 Kotlin 是基于 Stream 的,所以同样不支持动态数据结构,必须先定义结果的数据结构再计算,显得尤其复杂。
此外 Kotlin 也无法实施关联计算,加上无法热切换,作为微服务的数据处理工具其应用效果并不理想。
关于 Kotlin 数据处理能力更多可以参考《kotlin 能在 JAVA 中取代 SQL 吗》
Python
在数据处理方面不得不提 Python,其提供的诸多计算类库极大方便了各类数据处理场景,而 Pandas 又是结构化数据处理方面的翘楚。不过,Python 独立于 Java 体系并不能直接嵌入 Spring Cloud 提供数据处理能力,这时需要借助 Spring Cloud 提供的第三方语言整合接口(Sidecar)来集成 Python 计算服务。简单来说,Sidecar 就是 Spring Cloud 提供的一个工具,使用该工具将第三方的 REST 接口集成到 Spring Cloud 中来,从而实现 Java 与 Python 的双向通信。
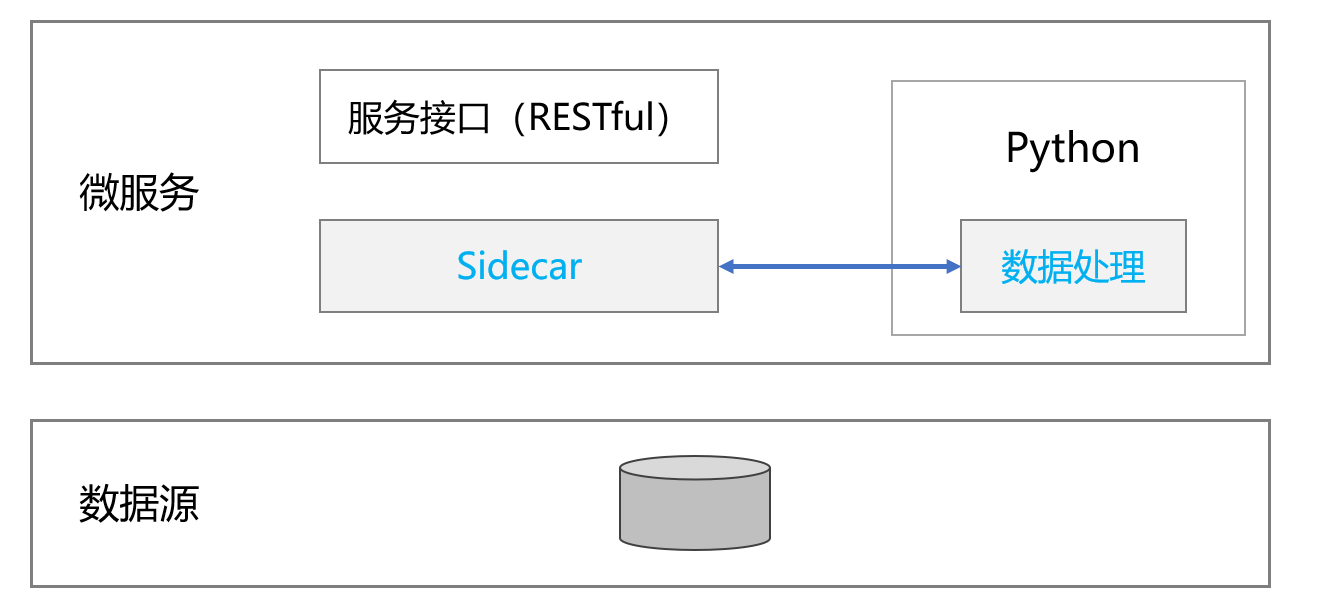
Pandas 实施大部分计算比较方便,比如实施关联计算,Python 中的关联是将两表根据某个或者某些字段连接在一起,组成一张宽表,这和 SQL 类似,但由于支持分步可以一步一步计算下来,思路清晰,代码也好理解。
但是,对于外键关联,Python 的处理方法有这样一些问题:
1.Python 的 merge 函数一次只能解析一个关联关系,在关联关系较多时比较麻烦。
2. 每次解析关联后得到的是一个新表,数据会被复制,耗时且耗内存;这个问题同维表关联时也存在。
3. 当发生自关联(循环关联)时,其本质还是两表关联得到新表,不可以重复利用已经建立好的关联关系。
关于 Pandas 在结构化数据计算方面还有哪些缺点,可以参考《Pandas 不擅长的结构化数据运算》。
另外,Python 完成微服务数据计算时工程上的问题也不容忽略,虽然通过 Sidecar 可以进行互通,不过远没有 Java 生态的解决方案(无论是原生的还是嵌入的)来的直接,维护成本也高。
集算器 SPL
集算器 SPL 是专业的开源数据计算引擎,可以将其视为增强型 Java 计算库,支持与 Spring Cloud 无缝集成实现微服务数据处理任务。集成时只需引入集算器相应 jar 包即可使用。具体集成使用步骤请参考《Spring Cloud 集成 SPL 实现微服务》。

数据源方面,集算器支持多种数据源类型,RDB、NoSQL、Json、CSV、Webservice 等,这方面远优于一般 Java 计算库。
在数据处理算法实现方面,集算器采用自有的 SPL 语法,下面的例子可以感受到 SPL 的简洁程度。
根据股票记录表查询股价连续上涨超过 5 天的股票及上涨天数(股价相等记为上涨)
| A | ||
| 1 | =connect@l("orcl").query@x("select * from stock_record order by ddate") | |
| 2 | =A1.group(code) | |
| 3 | =A2.new(code,~.group@i(price<price[-1]).max(~.len())-1:maxrisedays) | 计算每只股票的连续上涨天数 |
| 4 | =A3.select(maxrisedays>=5) | 选出符合条件的记录 |
这个例子即使使用 SQL 也要嵌套 3 层子查询才能实现(有兴趣的读者可以写写看),更不用说 Java(Stream,也包括 Kotlin)了。SPL 支持分步计算,这方面要优于 SQL。
值得一提的是,SPL 是解释执行的,支持热切换,计算脚本修改无需重启服务,这点是其他编译型语言无法比拟的。
此外,SPL 的拥有完备的计算能力,可以完成所有数据处理任务。关于 SPL 的更多内容可以参考:《SPL 学习资料》。
综合来看,使用 Spring Cloud 等 Java 微服务框架实施数据处理时,Stream 和 Kotlin 的实现复杂度最高,这是由 Java 一直缺少结构化计算类库导致的,虽然在慢慢变好但目前还远远不够;Java 计算库则往往不够成熟;而 SQL 由于数据库在微服务中的限制很难承担数据处理工作;Scala 本身使用难度较高;Python 虽然计算类库丰富但很多运算实现并不容易,且与 Java 框架结合需要较高的工程成本也不理想。集算器 SPL 几乎结合了其他实现方式的所有优点,具备 all-in-one 的特征。相对 SQL,SPL 支持分步计算实现复杂计算更加简单;相对 Java 则提供了丰富的计算类库,算法更加简洁;相对 Scala 又更简单;相对 Python 除了语法简洁又可以与微服务框架无缝嵌入更易使用。因此,SPL 用于实现微服务的数据处理更加理想。
