Salesforce 的再统计技术
SalesForce.com(SFDC)本身的报表有时不够丰富,需要把数据取出来,用其它技术手段再次统计,在SFDC之外做成报表。SFDC提供有restful json和soap xml标准取数接口,做报表也有大量早已成熟的工具,这两方面都没有明显的困难。但再统计技术的种类较多,用法区别较大,使用适合的再统计技术,往往是整个开发工作的关键。
用高级语言(C# /JAVA)编程进行再统计是很自然的事情,但编程语言缺乏统计计算类库,所有细节都要硬编码完成,工作量巨大、技术要求高、维护成本高,很少用到。实际项目中,较常用到的再统计技术有三种,下面依次说明。
报表工具的统计模块
统计的过程通常在报表数据源中完成,但有时也需要在报表中进行再统计,比如同一份数据既要展示明细又要展示汇总值,或对SFDC对象和Oracle表先做关联再做展示,类似的情况就需要用到报表工具的统计模块。下图是常见的统计模块:
少数报表工具内置了restful json或soap xml接口,可直接访问SFDC,常见的有tableau\IBM cognos\微软power BI等。另外,Excel2019也内置了访问SFDC的模块,适合制作格式固定的一次性(非程序性)报表。这个接口也可以独立出来,再封装成JDBC\ODBC driver的形式,供其他不直接支持SFDC接口的报表工具使用。可以使用商用driver,如IBM\informatica\jdata的产品,也可以用ascendix salesforce-jdbc这样的开源项目。
统计模块的优点是方便易用,其操作风格符合业务人员的习惯,通常会提供直观的拖拽或友好的向导。
但是,统计模块的缺点是能力较弱,只能进行一些简单计算,比如排序、过滤、分组、汇总、计算列等,远达不到SQL的计算能力,类似子查询(from (SQL))、临时表(with)、窗口函数(over)这样的计算都是难以实现的。
入库后的SQL统计
SQL的计算能力比报表强得多,所以有人把SDFC的数据先导入到数据库,再借助SQL的能力进行再统计。下图是常见的入库配置界面。
如果强调大批量和图形化,可采用ETL工具入库,比如informatica\datastage\kettle。如果介意采购成本,也可用SFDC driver+编程的方式入库。
SQL的优点是计算能力强,可以轻松实现子查询、临时表、窗口函数这样的计算,可以提供报表所需的绝大多数统计算法。
入库后再用SQL统计,实时性难以保障,这对某些项目而言是致命的缺点。用ETL工具入库,系统架构会变得沉重复杂,从制作报表的目标来看经常得不偿失。用编程+driver的方式入库,开发成本会很高,甚至远高于报表制作的成本。
Python
Python内置了结构化计算类库,拥有等价或优于SQL的计算能力,同时也具备取数接口,这就使SFDC取数、再统计这两个过程一气呵成,避免了入库的诸多缺点,实时性得到有效保障,架构变得简单轻便,开发成本也回归合理区间。
Python的能力主要来源于第三方类库,其中,结构化计算能力由Pandas提供,访问SFDC的能力可由Beatbox或simple-salesforce提供(前者更常用些)。下面的代码从SFDC查询内置的Lead表取部分数据,并转化为结构化对象DataFrame:
import beatbox
import pandas as pd
sf_username = "your name"
sf_password = "your password"
sf_api_token = "your token"
sf_client = beatbox.PythonClient()
password = str("%s%s" % (sf_password, sf_api_token))
sf_client.login(sf_username, password)
lead_qry = "SELECT Name, Country, CreatedDate FROM Lead limit 5"
query_result = sf_client.query(lead_qry)
records = query_result['records']
df = pd.DataFrame(records)
使用DataFrame,可轻松实现常见运算:
df.query('salary>8000 and salary<10000') #过滤
df.sort_values(by="salary",ascending = True) #排序
df.groupby("deptid")['salary'].agg([len, np.sum, np.mean]) #分组汇总
Pandas的结构化计算能力较达到甚至超过了SQL,即使一些较复杂的运算也可以实现。比如DateFrame duty是每日的值班情况:
| Date | name |
| 2018-03-01 | Emily |
| 2018-03-02 | Emily |
| 2018-03-04 | Emily |
| 2018-03-04 | Johnson |
| 2018-04-05 | Ashley |
| 2018-03-06 | Emily |
| 2018-03-07 | Emily |
| … | … |
一个人通常会持续值班几个工作日,之后再换人,现在要依次计算出每个人连续的值班情况,部分结果如下:
| name | begin | end |
| Emily | 2018-03-01 | 2018-03-03 |
| Johnson | 2018-03-04 | 2018-03-04 |
| Ashley | 2018-03-05 | 2018-03-05 |
| Emily | 2018-03-06 | 2018-03-07 |
| … | … | … |
实现上述计算的主要代码如下:
#省略获取duty的过程
name_rec = ''
start = 0
duty_list = []
for i in range(len(duty)):
if name_rec == '':
name_rec = duty['name'][i]
if name_rec != duty['name'][i]:
begin = duty['date'].loc[start:i-1].values[0]
end = duty['date'].loc[start:i-1].values[-1]
duty_list.append([name_rec,begin,end])
start = i
name_rec = duty['name'][i]
begin = duty['date'].loc[start:i].values[0]
end = duty['date'].loc[start:i].values[-1]
duty_list.append([name_rec,begin,end])
duty_b_e = pd.DataFrame(duty_list,columns=['name','begin','end'])
Python的优点的确亮眼,但缺点也很明显——没有能被报表工具方便调用的接口。报表工具几乎都是JAVA或.net体系下的,易于调用的接口是JDBC\ODBC,退而求其次可以用JAVA或C#编写的自定义数据集。遗憾的是,这里两种接口Python都不具备。虽然有一些方法可以在自定义类数据集里间接调用Python(如PyObject),但成熟度和稳定性都令人怀疑,实践中很少用到。
集算器 SPL
与Python类似,集算器 SPL也是开源的数据计算语言,并且内置了访问SFDC的接口和丰富的结构化计算类库。比如查询Lead表的部分数据,SPL代码如下:
| A | |
| 1 | =sf_open("D:\\raqsoft64\\extlib\\SalesforceCli\\user.json") |
| 2 | =sf_query(A1,"/services/data/v51.0/query","SELECT Name, Country, CreatedDate FROM Lead limit 5") |
| 3 | =sf_close(A1) |
其中user.json保存着salesforce的账号信息(username/password/api_token等)。A2直接就是SPL的结构化数据对象序表,而无须像Python那样转化。使用序表,可以轻松实现常见运算:
| A | B | |
| 4 | =A2.select(salary>8000 && salary<10000) | /过滤 |
| 5 | =A2.sort(salary) | /排序 |
| 6 | =A2.groups(deptid;sum(salary),avg(salary)) | /分组汇总 |
SPL的结构化计算能力较强,即使一些较复杂的运算也可以轻松实现。比如根据序表duty计算出每个人连续的值班情况,主要代码如下:
| A | |
| 1 | //省略获取duty的过程 |
| 2 | =duty.group@o(name) |
| 3 | =A2.new(name,~.m(1).date:begin,~.m(-1).date:end) |
SPL还有一个明显的优点——提供JDBC\ODBC接口,能被各类报表工具方便调用。比如把SPL代码存为脚本文件run.dfx,就可以在报表中以存储过程的形式调用,类似下面BIRT报表的用法:
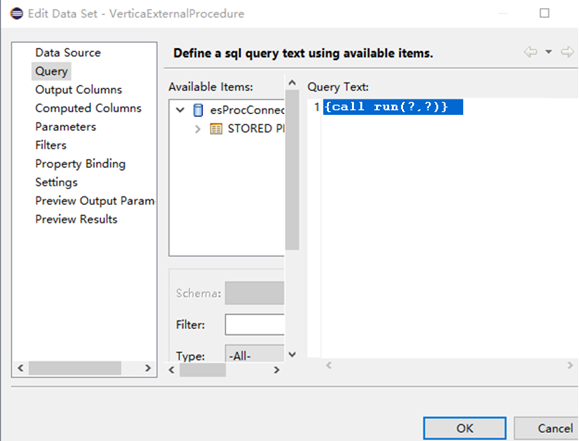
现在可以得出结论:在salesforce的再统计技术中,Python和集算器 SPL比报表工具的计算能力强得多,又比入库后的SQL实时性好、架构简单、开发成本低。其中,SPL还提供了JDBC/ODBC接口,更容易被报表调用。
