适合分析师的 SQL on file 工具
无论程序员,还是数据分析师或科研工作者,有很多人都会编写SQL。无论单机上的access,还是局域网中的mysql 或云环境中的Hadoop,也有很多平台都支持SQL。经过半个多世纪的演化,SQL已是应用广、成熟度高、使用方便的数据查询语言。
但有时候数据在CSV/TSV/XLS之类的文件里,为了能继续使用熟悉的SQL,我们不得不先把文件导入数据库。这个过程很麻烦,要建立表结构、设定字段名和数据类型、分配权限,再等待加载。如果涉及多个文件导入,这个过程就会变成更为耗时耗力的重复劳动。文件越多体积越大,还要应对表空间不足的问题。有些文件经常更新变化,就不得不反复导入,这都令人难以忍受。
更麻烦的是,还有些文件就不能导入数据库,或者勉强导入也没法用,还不如用Python或JAVA等开发语言直接计算。常见的情况有:开头或结尾的数据无用、分隔符不规范(不可见字符、双字符)、文本格式不规范。比如一行对应多条记录的情况:
name,state,trips Smith,Colorado,2020-01-02 2020-01-05 2010-02-03 Jeff,Connecticut,2020-01-09 Smith,Indiana,2020-01-21 2020-02-10
此外,大部分数据库都不支持导入xlsx,需要安装Excel或第三方工具。安装Excel的话,需要将xlsx转为csv再导入数据库,烦;用第三方工具直接导入的话,环境配置复杂,有的只支持xls,有的只支持低版本的xlsx,更烦。
总之,文件入库是个麻烦不断的过程。
那么,有没有能直接针对文件执行SQL的工具?
可以想象,如果能在文件上直接执行SQL,就能避开入库带来的一切麻烦,大大提高工作效率。由此还能带来更大的好处:再也不必为了计算文件,而专门部署和维护一套数据库系统。
优点如此显著,工具自然不缺。
但先别高兴太早。号称能直接针对文件执行SQL的工具,或多或少都会存在一些缺陷,有些缺陷还很致命。下面,让我们先从轻便的命令行工具开始,深挖一下各类工具的真实能力。
csvsql
既然是命令行工具,csvsql必然具备短小快捷的优点,比如带列名的sales.csv文件,按client列分组,对每组的amount列求和,只需在命令行简单写一句:
D:\csvkit\csvsql\bin> csvsql --query "select client, sum(amount) from'sales'group by client" salse.csv
遗憾的是,csvsql除了体积小、编写SQL快捷之外,就只剩缺点了,其中很大的缺点是安装配置复杂。csvsql本质上不是独立程序,而是个Python脚本,所以必须事先配置好Python环境,又因为许多功能依赖第三方,所以还要下载合适版本的函数库。这些对程序员来说还算容易,但对数据分析师来说,就有点太为难了。
csvsql的第二大缺点是没有自己的计算引擎。csvsql内置了一个SQLite数据库,当我们敲完SQL后,csvsql先以IN-MEMORY模式启动SQLite,然后默默建表,并将文件全部加载到SQLite,接着把针对文件的SQL翻译成针对数据库表的SQL,再执行翻译后的SQL。
没有自己的计算引擎,首先会导致SQL能力不足。csvsql必须根据SQLite的语法设计一套自己的SQL,还要将针对文件的SQL翻译成针对库表的SQL,没有强大的技术实力,自己设计的SQL就会趋于保守,翻译的过程也很难面面俱到,所以csvsql丢失了很多基本功能,比如模糊查询和日期函数,而这些功能SQLite原本是支持的。
没有自己的计算引擎,还导致计算性能不足、文件体积受限。每次执行SQL时,csvsql并非直接对文件计算,而是多了一步导入内存的过程,加上类型转换,耗费的时间会相当可观,因此计算性能较差。文件从硬盘到内存后,体积会变大很多,如果文件较大而机器内存较小,不仅加载时间漫长,还可能发生内存溢出,所以文件不能太大。
归根到底,上面两大缺点是因为技术实力不行,所以,下面更多的缺点就不难理解了。
第三点:只支持文本文件,不支持日常工作中很常见的Excel。
第四点:对文本格式要求太严。csvsql只能读取较基本的CSV格式,如果要实现定义分隔符、跳过无用行、区分首行列名等常用功能,就只能借助其它文本编辑工具进行预处理。如果开头或结尾的数据无用、分隔符不规范(不可见字符、双字符)、文本格式不规范,则须借助Python、JAVA等开发语言进行预处理。
类似csvsql的命令行工具还有不少,比如textql、querycsv.py、q,这些工具虽然略有差异,但因为基本原理类似,所以上面的缺点一个都不少。
虽然命令行工具都没有自己的计算引擎,但有一类工具一定有,那就是数据库系统。下面让我们看看HSQLDB,一款相当常见、且能直接针对文件执行SQL的数据库系统。
HSQLDB
数据库本身就是技术实力的表现,所以HSQLDB不仅有自己的计算引擎,还提供了强大的SQL语法,无论关联查询、子查询,还是模糊查询、日期函数,HSQLDB一个都不少,这一点是命令行工具无法比拟的。
但安装、管理、维护数据库是一件很麻烦的事,尤其是维护,我们不仅要分配权限、硬盘、内存、缓存,还要配置各种各样的复杂参数,这些工作对数据分析师来说相当困难。事实上,我们之所以希望在文件上直接执行SQL,很重要的一个原因就是为了避开数据库的维护。
不仅日常的维护和管理麻烦,在文件上执行SQL时,操作步骤仍然复杂。
启动HSQLDB的服务器和客户端(也可用第三方客户端工具比如SQuirreL SQL)的命令格式就很复杂
D:\jre1.8\bin>java –Xms128m –Xmx2403m -cp d:\hsql\hsqldb.jar org.hsqldb.server.Server -database.0 file: d:\hsql\database\demo -dbname.0 demo D:\jre1.8\bin>java -Xms128m -Xmx2403m -cp d:\hsql\hsqldb.jar org.hsqldb.util.DatabaseManager
这东西,不熟悉java的非专业程序员都会望而生畏。
客户端连接服务器的参数配置也很复杂:
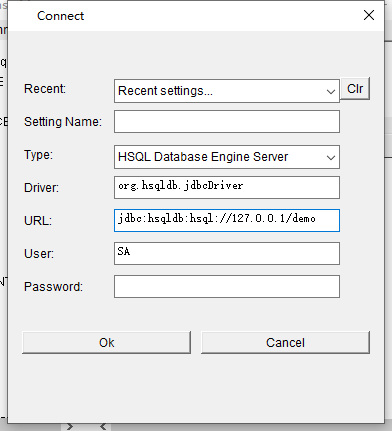
还要执行多条预处理语句,包括删除可能存在的表名、新建表结构、将文件对应到表,才能真正执行SQL。其中,将文件对应到数据库表时,需配置大量参数,如下:
SET TABLE sales SOURCE "sales.csv;fs=,;encoding=UTF-8;quoted=false;ignore_first=true; cache_scale=100";
除了操作过程复杂,HSQLDB还有很多不合理之处。HSQL不支持自动解析数据类型,把这个麻烦扔给了用户,让用户自己建表结构。为了方便使用,很多文件的首行都是字段名,尤其是csv,但HSQLDB要求用户建表结构并指定字段名,这就导致文件首行的字段名完全无用。我们的启动方式明明是server而不是in-memory,但HSQLDB却会把文件事先缓存到内存,这就会影响整体性能,尤其是文件较大时。
可以看到,HSQLDB虽然有自己的计算引擎,但底层核心仍然是数据库表,并非真正的文件计算引擎,所以才会出现诸多不合理之处。由于缺乏真正的文件计算引擎,所以HSQLDB不支持Excel,不支持常见的文本格式,更不支持不规范的文本格式等等。
与HSQLDB类似,H2 database和PostgreSQL也可以针对文件执行SQL,操作过程虽然迥异,但基本原理没大区别,所以优点缺点如出一辙,这里不再赘述。
数据库缺乏真正的文件计算引擎,而且从安装管理到配置执行都很复杂,那有没有既有文件计算引擎,还有友好的交互界面,可大幅降低使用难度的桌面工具呢?还真有,下面会讲到。
OpenOffice Base
作为桌面工具,OpenOffice Base的易用性令人印象深刻:一键安装,即安即用无须配置;界面友好,操作快捷交互流畅。
不仅外表易用,OpenOffice Base的内核也很强大,因为它有真正的文件计算引擎,可以对文件直接计算,而不必将文件加载到其他数据库,也不必用数据库引擎计算文件。这就带来了三个明显的改进:自动识别文件中的数据类型,可计算超过内存的大文件,整体性能大幅提高。
可惜的是,这个文件计算引擎并不完善。
第一,OpenOffice Base只支持文本文件,不支持日常工作中很常用的Excel,这就大大限制了使用场景。
第二,OpenOffice Base的SQL能力极为有限,很多基本功能无法实现,比如下面的关联查询:
select employee.name, sales.orderdate, sales.amount from sales left join employee on sales.sellerid= employee.eid
第三,对文本格式限制过多。
除了默认格式,不支持任何其他格式的数据类型,比如下面特殊格式的日期:
orderid,client,sellerid,amount,orderdate 1,UJRNP,17,392.0,01-01-2012 2,SJCH,6,4802.0,31-01-2012
不支持特殊分隔符,比如下面的格式:
orderid||client||sellerid||amount||orderdate 1||UJRNP||17||392.0||2012-01-01 2||SJCH||6||4802.0||2012-01-31
复杂情况就更不能处理了,比如下面的格式:
producer: allen date:2013-11-01 //前两行无用 26 //以下为多行记录 TAS 1 2142.4 2009-08-05 33 DSGC 1 613.2 2009-08-14
如果对格式标准的文本文件进行很基本的查询,OpenOffice Base是首选工具,但实际工作和理想环境不同。在实际工作中,我们会经常遇到Excel,文本格式总是各式各样,SQL算法也应自由灵活。如何才能在实际工作中对文件执行SQL呢?那当然是文件计算引擎较为完善的工具了,准确地说,是下面要讲到的编程语言集成组件。
Microsoft text/xls driver
作为实力大厂出品的编程语言集成组件,Microsoft text/xls driver几乎无所不能。在SQL语法方面,该组件不仅支持模糊查询、日期函数,也支持子查询和关联查询,基本覆盖实际工作所能遇到的各种算法。比如关联两个csv文件:
select client.clientname, sales.orderdate, sales.amount from [sales.csv] as sales left join [client.csv] as client on sales.clientid=client.clientid
文件类型方面,该组件不仅支持TXT/CVS/TVS,也支持XLS/XLSX,而且没有版本限制,这一点在实际工作中非常便利。
对于常见的文本格式,该组件支持得非常好,比如定义分隔符、区分首行列名、设置固定宽度的列、自动识别数据类型。对于复杂的文本格式,该组件虽然不能直接处理,但能通过编程间接计算。理论上来说,程序员可用该组件读取任何文本格式,可实现任意业务算法。
Microsoft text/xls driver的文件计算引擎较为完善,从能力上来说缺陷很少,但它是程序员的专业工具,并不适合数据分析师。
第一,该组件的技术门槛很高,要想正常使用,必须掌握一门编程语言,比如C#或VB。在熟悉编程语言的基础上,还需要学会ODBC、OLEDB、ADO这三种具体的编程接口之一。
第二,该组件需要编写大量难懂的代码,才能真正执行上面的提到的SQL语句。简化后代码如下:
string path= string.Empty;
path="d:/data";
if (string.IsNullOrWhiteSpace(path)) returnnull;
string connstring = string.Empty;
connstring = "Provider=Microsoft.ACE.OLEDB.12.0;Data Source=" + path + ";Extended Properties='text;HDR=YES;FMT=Delimited';";
DataSet ds = null;
OleDbConnection conn = null;
try
{
conn = new OleDbConnection(connstring);
conn.Open();
OleDbDataAdapter myCommand = null;
myCommand = new OleDbDataAdapter(strSql, connstring);//在这里执行SQL
ds = new DataSet();
myCommand.Fill(ds, "table1");
}
catch (Exception e)
{
throw e;
}
finally
{
conn.Close();
}
return ds;
第三,该组件扩展困难。上面的代码只能适用于较规范的文本文件,如果要定义字符串格式或数据类型,还需使用schema.ini配置文件。如果要解析复杂的文本格式,还需额外编写大量代码。
除此之外, Microsoft text/xls driver还存在一个问题:text driver和xls drvier虽然用法类似,却是两个独立的组件。换句话说,文本文件和Excel之间不能进行关联计算,除非额外编写大量代码。
与Microsoft text/xls driver类似,CSVJDBC/ExcelJDBC、SpatiaLite也是支持在文件上直接执行SQL的编程语言集成组件,虽然语言环境不同,但基本原理类似,所以使用难度都很高。而。且这两种组件不是实力大厂的产品,比起Microsoft text/xls driver要差上不少。
Microsoft text/xls driver的文件计算引擎虽然完善,但使用难度很高。OpenOffice Base易用,但文件计算引擎不够完善。那有没有兼具二者优点,适合数据分析师使用的工具呢?要求苛刻,中者寥寥,目前只发现下面这么一款产品。
集算器 SPL
集算器 SPL是开源的计算引擎。与OpenOffice Base类似,它同时也是个易用的桌面型工具,一键安装无需配置。比OpenOffice更易用的是,集算器 SPL可以在单元格直接编写多条SQL,计算结果和SQL直接呈现在同一界面,点击SQL所在的单元格可切换观察计算结果。
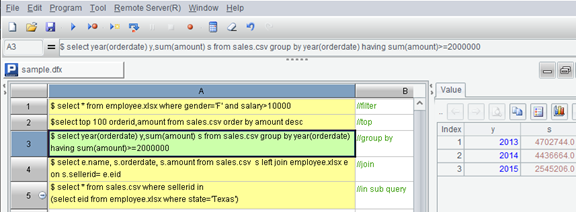
与Microsoft text/xls driver类似,SPL具有完善的计算引擎,可支持实际工作所能遇到的各种SQL语法(见上图),这是OpenOffice Base做不到的。
文件类型方面,SPL支持TXT/CVS/TVS,也支持不同版本的XLS/XLSX。比Microsoft text/xls driver更强大的是,SPL可以直接对文本文件和Excel进行关联计算(见上图)。
除了规范的文件格式外,SPL还可以利用扩展函数应用更复杂的情况。比如分隔符为"||"的文件,OpenOffice Base无法解析,Microsoft text/xls driver要编写大量代码,而集算器只需在SPL中使用扩展函数:
$select * from {file("sep.txt").import@t(;,"||")}
SPL可自动识别数据类型,对于非默认格式的数据,比如前面提到的特殊日期,OpenOffice Base无法解析,Microsoft text/xls driver需用schema.ini配合代码实现,而SPL只要使用简单的扩展函数就能轻松应对:
$select * from
{file("style.csv").import@ct(orderid,client,sellerid,amount,orderdate:date:"dd-MM-yyyy")}
格式复杂的文本,比如前面提到的一行文本对应多条记录的情况,OpenOffice Base无法解析,Microsoft text/xls driver需资深程序员编写大量复杂代码,而使用扩展函数后SPL也不难处理:
$select * from
{file("trip.csv").import@tc().news(trips.array(" ");name,state,~:trip)}
分析过十几种工具之后,我们可以得出最终结论:号称支持文件上直接执行SQL的工具中,绝大多数只是徒有其表,真正可用的其实只有Microsoft text/xls driver和集算器 SPL,前者只适合程序员,后者才适合数据分析师。
